Configure OpenAI Playground for better results

System area
The 'system area' typically provides a scripting interface that allows users to fine-tune the AI model by specifying custom configuration parameters, setting up constraints, or defining additional rules. It enables users to have a higher degree of control over the AI's output and guide its responses to generate more relevant or desired results.
By utilizing the system area, users can tailor the AI model's behavior to align with their specific needs or preferences, making the AI system more adaptable and personalized.
User area
The 'user area' refers to the interactive environment where users can write code and experiment with the available models and APIs provided by OpenAI. It is the section of the playground where users can input text, make queries, customize parameters, and receive responses and outputs from the models in real-time. The user area allows users to directly interact with the AI models and observe the results, facilitating the exploration and development of various applications and use cases.
Assistant area
The 'assistant area' in the OpenAI playground refers to a user interface element where users can interact with OpenAI's language model, also known as the GPT-3 model. It allows users to type in prompts or questions and receive generated text responses from the language model. The assistant section offers a conversation-style interaction, where multiple messages can be exchanged back and forth between the user and the model. Users can specify the role of the user and assistant (model), and can also include system-level instructions to guide the model's behavior. The assistant section is designed to provide an intuitive and interactive way for users to engage with the powerful language model offered by OpenAI.
Controls available on the OpenAI playground interface

Your prompts can be save (Save button) and retrieved from the 'Your Presets' dropdown. the View code button will generate a Python script with the current parameter values (see Behind the scenes section below). The share button will allow user to share a preset by publishing a shareable link. The '...' button can be use to delete a preset,
Mode
In the context of OpenAI Playground, 'mode' refers to the different settings or configurations available for the AI model. The mode determines the behavior and capabilities of the model when generating responses to user inputs.
There are typically three modes available in OpenAI Playground:
'ChatGPT': This mode allows for interactive conversations with the AI model. Users can have back-and-forth exchanges with the model by providing a series of messages as input. Each message consists of a role ('system', 'user', or 'assistant') and the content of the message. This mode is useful for simulating chat-based interactions.
'Story': In this mode, users can create a narrative or story by providing a series of prompts. The model will generate a continuation based on the given prompts. This mode is suitable for generating creative writing or exploring different storylines.
'Question-Answering': This mode is designed specifically for asking questions and receiving answers from the model. Users can provide a context or passage, followed by a question related to the context. The model will generate a response that attempts to answer the question based on the given context.
By selecting the appropriate mode, users can tailor the AI model's behavior to suit their specific needs and desired interaction style.
Model
A 'model' refers to a pre-trained artificial intelligence system that can generate text based on the given input. These models are trained on a vast amount of data and are capable of understanding and generating human-like text. The models in OpenAI playground are designed to assist users in various tasks such as writing, brainstorming, or generating creative content. Users can interact with the model by providing prompts or instructions, and the model will generate text based on the input. The models in OpenAI playground are continuously updated and improved to provide better results and enhance the user experience. Examples of models : Chat, GPT-3: GPT-3 (Generative Pre-trained Transformer 3), ChatGPT, Codex. InstructGPT among others. You may not see all of these models since OpenAI will deprecate some of them.
Temperature
'Temperature' refers to a parameter that can be adjusted when generating text using the GPT-3 model. It controls the randomness of the generated output.
A higher temperature value, such as 0.8, makes the generated text more diverse and creative, as it allows for more random choices. This can result in more unexpected and imaginative responses. However, it may also lead to less coherent or logical output.
On the other hand, a lower temperature value, such as 0.2, makes the generated text more focused and deterministic. It tends to produce more conservative and predictable responses, often sticking to more common patterns and phrases.
By adjusting the temperature, users can fine-tune the balance between creativity and coherence in the generated text, depending on their specific needs and preferences.
Maximum length
'Maximum length' refers to the maximum number of tokens allowed in an input text. Tokens can be individual words, characters, or subwords depending on the language and tokenization method used. The 'Maximum length' setting helps limit the length of the input text to ensure efficient processing and prevent excessively long inputs that may exceed computational limits. If the input text exceeds the specified maximum length, it may need to be truncated or shortened to fit within the allowed token limit.
Stop Sequences
'Stop sequences' refer to specific input text that is used to indicate the end of a generated response. When generating text using models like GPT-3, you can provide a 'stop sequence' to instruct the model to stop generating text once it encounters that particular sequence.
For example, if you provide the stop sequence as "###", the model will generate text until it reaches the first occurrence of "###" in the generated output. Anything beyond that stop sequence will not be included in the response.
This feature is useful when you want to control the length or specificity of the generated text. By setting a stop sequence, you can ensure that the model stops generating text at a desired point, preventing it from going on indefinitely.
Top-p

Nucleus sampling, also known as top-p sampling or top-k sampling, is a technique used in artificial intelligence (AI) for generating text or sequences of data. It is commonly employed in natural language processing (NLP) tasks such as language generation or text completion.
In nucleus sampling, instead of selecting the next word or token based on a fixed probability threshold, a dynamic threshold is used. The technique involves ranking the probability distribution of the possible next words or tokens and then selecting from a subset of the most likely candidates.
The subset, or nucleus, is determined by a cumulative probability threshold, typically denoted as p. The top-k words or tokens with the highest probabilities are considered, where k is the smallest number that satisfies the condition that the cumulative probability of the selected words exceeds p. This means that the size of the nucleus can vary depending on the probability distribution of the words or tokens.
By using nucleus sampling, the generated text or sequence tends to be more diverse and avoids repetitive or overly deterministic outputs. It allows for a balance between randomness and control, as it ensures that the generated content is still coherent and meaningful while introducing some level of variability.
Nucleus sampling has been widely used in various AI applications, including language models, chatbots, and text generation
Frequency penalty
In the context of the OpenAI playground, 'frequency penalty' refers to a parameter that can be adjusted to control the level of repetition in the generated text. It is used in conjunction with the 'temperature' parameter to fine-tune the output of the language model.
When the frequency penalty is set to a higher value, the model is penalized for generating repetitive or redundant text. This encourages the model to produce more diverse and varied responses. On the other hand, a lower frequency penalty allows the model to generate more repetitive text.
By adjusting the frequency penalty, users can influence the balance between generating creative and novel responses versus generating more coherent and consistent text.
Presence penalty
The term 'presence penalty' refers to a parameter that can be adjusted when using the ChatGPT model. It is used to discourage the model from generating long, repetitive, or unnecessary responses.
The presence penalty works by penalizing the model for repeating similar phrases or ideas within its responses. By increasing the presence penalty, the model is encouraged to provide more diverse and concise answers. On the other hand, decreasing the presence penalty may result in longer and more repetitive responses.
The presence penalty is a useful tool for controlling the behavior of the model and ensuring that it generates more coherent and varied responses during conversations.
Behind the scenes
For all these parameters there is a Python script that will talk to the model when you submit a prompt .You can use the following code to start integrating your current prompt and settings into your application.
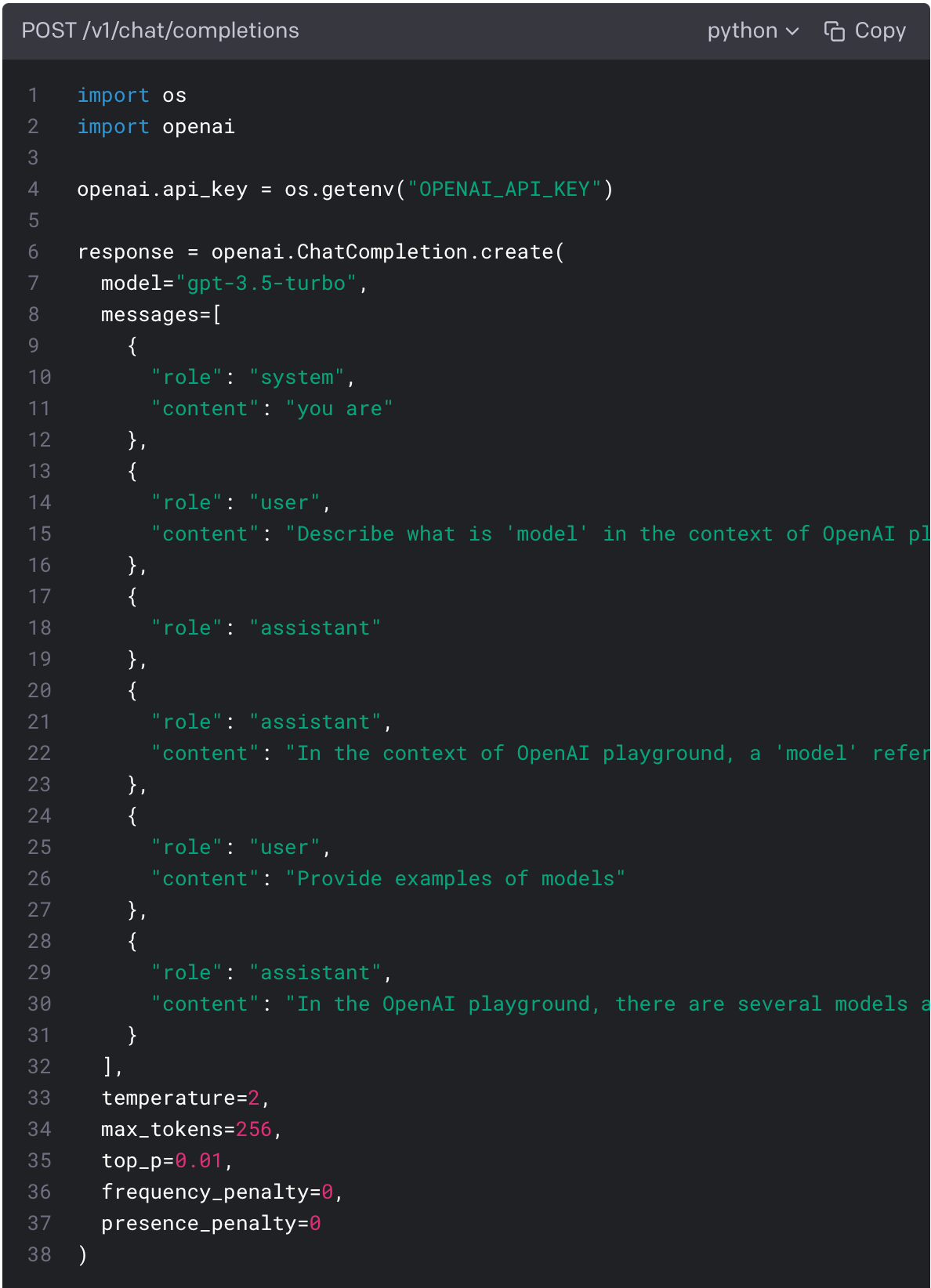
I hope that this article help you to understand how the OpenAI Playground works so that you can produce better results while writing your prompts.
Thank you,
Oscar Sosa